I last wrote about my project’s acceptance testing setup a year ago. At the time we had over 20 test suites that exercised a large part (but not all) of the code. In particular some of the longer-running operations (image creation, server resize) were not covered by our test suites. As we developed the site we continued to break behavior that was not covered by automated tests.
I still stand fully by the statement I made in that previous post:
If something is not tested at the acceptance level and consistently kept green, it will break.
This isn’t to say that unit testing isn’t valuable – it’s crucial for fast feedback. However, to truly mirror the customer experience, you must automate the user experience; if you don’t have automation around some aspect of the user experience, it will break.
We now have almost 100 test suites containing over 1200 user scenarios. We’ve added a lot more features in the last year, including role-based access control, an autoscaling solution, and a managed Hadoop offering. We’ve rolled out new experiences around image selection on server create and monitoring Cloud Databases. All of these changes have come “acceptance tests included”. Throughout these changes our deployment pipeline has remained broadly the same, with some minor differences: every hour, code is pushed to our preproduction environment, where our acceptance tests run. Rather than rely on Jenkins-only automation we use an IRC bot heavily. However, as we’ve grown both our suite and our team we’ve needed to adjust our strategies to scale our tests out.
I consider our test suite the major engineering success of our project. Four years ago the previous version of Rackspace Cloud Control Panel relied heavily on manual QE. Production pushes required in-depth manual regression which sometimes took weeks. Features were broken three days into a sprint and not discovered until two months later when a release candidate was being prepared. That latency from break to fix made deployment a huge headache; we’d have to manually port patches between different release branches. Today we run a full suite and detect these failures with a very fast turnaround. Issues that are detected result in a revert of the code, allowing us to develop and deploy the master branch daily. Rather than rely on a manually executed test matrix that different parts of the user interface behave as expected for different user types (account admin, product observer, etc), these tests automatically run every hour. Defects reported to the team must pass through the mental filter of ‘but the tests are passing’ – ruling out a large class of bug possibilities.
In this post I’d like to highlight the factors I believe were most important for our success and talk a bit about some specifics we’ve used to manage the complexity around the size of our test suite. As in my previous post, I’m not describing work that I myself uniquely did, but instead the work of the whole team (more than thirty individuals) over the last year.
What Have Been Our Major Success Factors?
I’ll single out two main factors that have lead to our current success.
Team Buy-In
A lot of effort goes in to creating and maintaining our tests. Stories are not done until developers have written tests. We don’t ship projects that haven’t had their automation finished. Automation is generally done as work is done, and not in a “big bang” at the end of a project. Bugs that affect automation are put onto the backlog and worked in instead of simply adding more features. Defects that escape to production have new automation associated with it. To gain the benefit from the tests the entire team (not just the “developers”!) needs to acknowledge that automated testing has benefits.
Developer Ownership of Automated Test Suite
Rather than our test suite being owned by a “testing” team, the test suite is owned and maintained by the development teams. Developers write tests. Developers fix tests. Development teams own test suites and bad behavior on the part of a test suite results in defects, with work done to fix them.
Contrast this with a situation where there is a special class of team member, the “automated tester”, who writes tests associated with features that “product developers” create. This separation forces a number of antipatterns: the team can only mode as fast as the automated tester can write the tests, defects in the testing suite can be overwhelming, and advances in testing strategy only come from a limited group of people.
We have automation specialists on our project. These team members provide guidance about which testing strategies are likely to work in a given situation. and have the experience to guide the testing “state of the art” move forward. However these are not the only team members that contribute to our team’s testing vision. Much of the infrastructure that our tests currently use, including tasks for account management and resource verification, came from team members who don’t wear the “automation specialist” hat.
Testing Strategies
I’ll now go into some of the details that allow us to maintain our suites. Maintenance is definitely the right attitude with regards to a functional test suite. Small changes can have a big impact and just like application code, test code needs to be kept modern through refactoring and other improvements. While test maintenance is a burden, it’s an important burden that enables us to push to production multiple times daily with confidence.
Run Smaller Suites in Parallel for Speed and Logical Cohesiveness
We’ve constantly been splitting our test suites into smaller and smaller test suites (one reason why we’re at 100 smaller test suites rather than 30 larger tests). “Servers” is the flagship product of Rackspace Public Cloud. Rather than have one large “Servers” test we have 15 smaller suites that only test individual parts of Servers functionality.
Acceptance_Servers_Creation_FirstGen
Acceptance_Servers_Creation_From_Image
Acceptance_Servers_Creation_NextGen
Acceptance_Servers_Creation_NextGen_Advanced_Options
Acceptance_Servers_Deletion_Firstgen
Acceptance_Servers_Deletion_Nextgen
Acceptance_Servers_Images
Acceptance_Servers_Networks
Acceptance_Servers_Managed
Acceptance_Servers_Other
Acceptance_Servers_Performance_Resize
Acceptance_Servers_Rebuild
Acceptance_Servers_Resize_FirstGen
Acceptance_Servers_Resize_Nextgen
Acceptance_Servers_SSH_Keys
To have one suite that tested all functionality would pose several challenges. First, it would run too long. Tests need to run fast. Our goal is for every acceptance test to finish in 10 minutes (we haven’t adhered exactly to this, but it’s an aspiration). Given 1 suite that takes 30 minutes to run, we’d split it up into 3 suites that take 10 minutes to run (in parallel), or even shard our tests even further.
Second, a test suite with 100 tests really doesn’t present a clear target for improvement. If a group of tests start failing it is hard to know where the area for improvement is (or where a code defect was introduced). Different tests have different fidelity: separating tests into logical groupings allows the fidelity of different features to come to light and be improved.
You Need Retries To Maintain a Large Suite
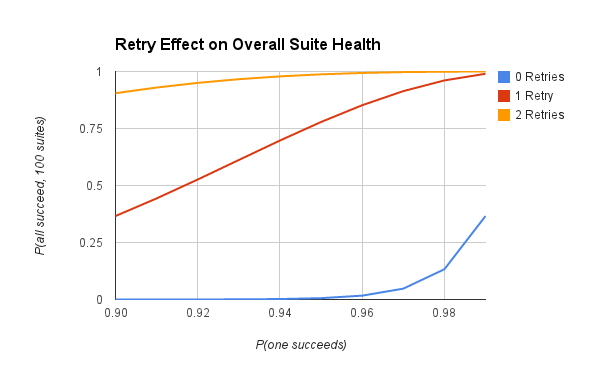
We use rspec-retry to filter out the noise from failing tests. Suppose your test suite has 99% reliability; 99 out of 100 times it passes. Adding retries to this test suite greatly improves its reliability.
P(1 suite passes, no retries) = 0.99
P(1 suite passes, 1 retry) = 0.99 + 0.01 * (0.99) = 0.9999
P(1 suite passes, 2 retries) = 0.99 + 0.01 * (0.99 + 0.01 * 0.99) = 0.999999
If you have a lot of suites, it’s easy to see that retries are essential for the overall health of your test suite.
P(all 100 suites pass, no retries) = (0.99)^100 = 0.366
P(all 100 suites pass, 1 retry) = (0.9999)^100 = 0.99
P(all 100 suites pass, 2 retries) = (0.999999)^100 = 0.9999
Of course this only really makes a big difference if your suite is already reliable. If you have a suite that passes 50% adding two retries only bumps it up to an 87% suite. If you run 100 suites at this reliability, you will constantly be dealing with failures.
P(pass no retries) = 0.50
P(pass 1 retry) = 0.50 + 0.50 * (0.50) = 0.75
P(pass 2 retries) = 0.50 + 0.50 * (0.50 + 0.50 * 0.50) = 0.875
P(all 100 suites pass, no retries) = (0.50)^100 = 7.88e-31
P(all 100 suites pass, 1 retry) = (0.75)^100 = 3.2e-13
P(all 100 suites pass, 2 retries) = (0.875)^100 = 1.58e-06
The only cost of adding retries is extra time. Retries for tests that run fast are almost completely free.
This isn’t to say that retries should be added in every situation. When developing a test, you’re probably not at a very high level of reliability. You need to dig into all the various reasons that a test could be written better, fix those, and only after this turn on retries. However, when dealing with a legacy test suite, adding another retry is a good way to make it behave slightly better until you have the time to invest possibly hours of development work into making it run better. (I recently rewrote a test suite over a 5 day period, on and off. Work to improve tests can sometimes take serious time and effort!)
Tests That Rely on Data
Certain of our automated tests rely on data already being set up. For example, the test to add a private network to a server requires an already-created server. We had a lot of issues attempting to “re-use” resources during test, specifically related to parallelizing tests. Two tests attempt to use the same resource results in nondeterministic test behavior.
In most situations we’ve changed our tests to create these resources before they execute and remove them when they are done. In certain situations where this can’t be done due to the length that it would take to set this up (for example, a test that needs a server with an image created) we have a verification job which ensures that the required resources for test execution exist. By keeping this test green, we reduce the amount of “why did this fail?” decisions that the team is required to make on a day-to-day basis.
No Test Doubles, Yet
We integrate with over 15 other services (RESTful APIs). We have found it most practical to automate against production quality services. However, sometimes these services have outages or don’t behave as we would otherwise expect. To remove the feedback in these cases, Integration Contract testing has been proposed in the past.
There are two main reasons why contract testing is a poor match for our project. The first is that these APIs are under active development and always changing; to keep up with the rate of change across all the teams we integrate with would be extremely difficult. Secondly, most of the APIs that we integrate with are provisioning APIs. The true mark of whether or not an API has “changed its contract” is whether or not resources make identical state transitions to the same requests and responses. If we are verifying a user story to create a server, let it become active, and attach a block storage volume, a test must wait a certain amount of time for the server to become active. That amount of time is part of the API’s “contract” but not part of the request and response format. Maintaining test doubles that duplicate the exact behavior of another team while changing in the face of constant development is a herculean task.
Because of this, we’re not utilizing test doubles yet. Recently there’s been an initiative for service teams to create test doubles as part of their day-to-day delevelopment, which would allow for us (a consumer) to more easily integrate test doubles in our pipeline. Even when this happens it will be in addition to rather than instead of: by testing against real APIs we’ve uncovered real problems and driven real improvement across the entire Rackspace Public Cloud offering. Though uncovering bugs in other services can be frustrating, moving to a double-only approach would completely cut off this source of product improvement and remove our team even further from the actual customer experience.
Final Thoughts
Not every project requires this amount of testing. However, the amount of features and the number of developers: over 20, with five development subteams, with new features added each day, make this level of testing extremely useful in implementing a CI/CD pipeline for our particular project.
We have a number of advantages in implementing our test suite. We are still in growth mode. Most of the project’s code is under three years old, meaning that we have very little “legacy” code. We have organizational buy-in to focus on work that improves quality as well as on new features. These advantages allow us to test with the depth and breadth required to constantly ship a large product without relying on dedicated testing cycles.